Parallel execution in practice
The best way to see what plan mode produces is to look at a concrete example. Adding a NewsAPI integration to the project involved changes across 8 files.
The scope
The full change set for the integration:
| File | What changed |
|---|---|
pyproject.toml | Added eventregistry dependency |
defs/resources.py | Added NewsApiResource class + registered "newsapi" |
defs/assets/trending_events.py | New partitioned asset |
defs/schedules/daily_raw.py | Split raw job, added partitioned schedule |
.env.example | Added NEWS_API_KEY |
dbt_project/models/staging/sources.yml | Registered trending_events source |
dbt_project/models/staging/stg_trending_events.sql | New staging model |
dbt_project/models/staging/schema.yml | Added not_null tests |
Eight files, spanning Python, dbt SQL, dbt YAML, and project config.
Why all 8 can be written simultaneously
Because the plan was complete before any file was written, the design was fully known at write time:
- The interface for
NewsApiResource: anapi_keyfield, aget_client()method returning anEventRegistryinstance - The DuckDB table schema: what columns
trending_eventswould land in - The partition definition: daily partitions, how they'd be referenced in the schedule
None of these files needed to wait for another to be written first. A resource definition doesn't depend on the asset file being complete; the dbt source registration doesn't depend on the Python asset existing yet. All 8 can be written in a single message.
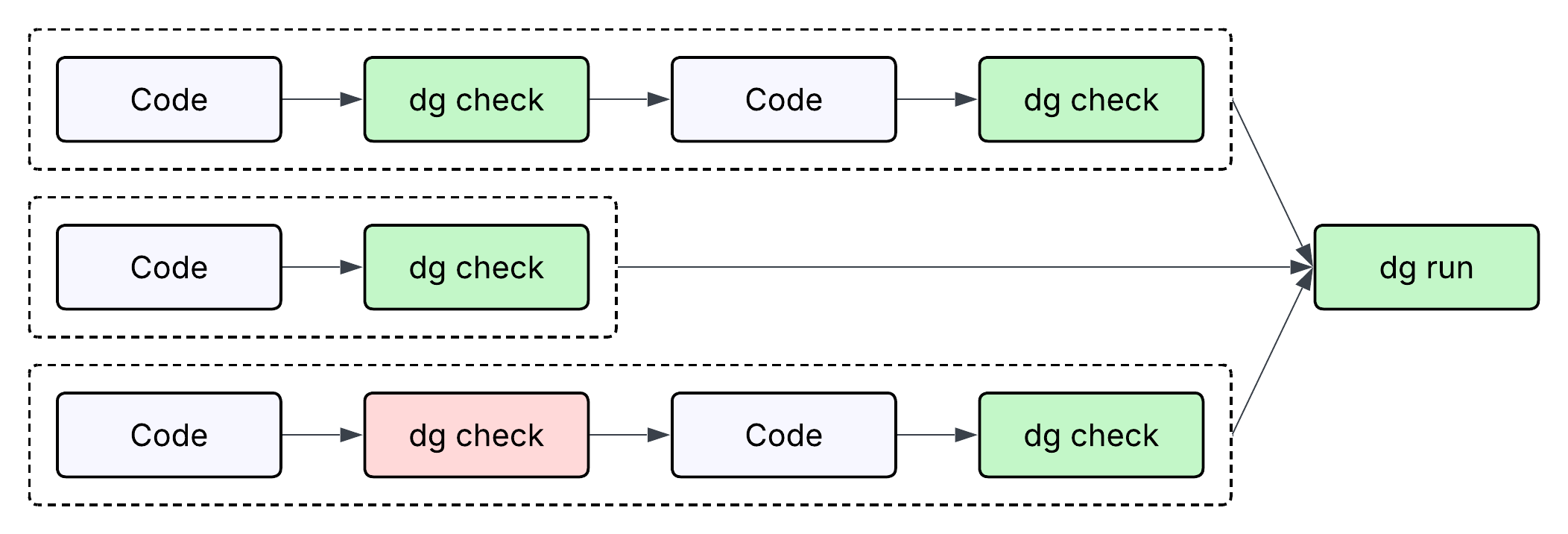
Validation as the final sequential step
After the parallel writes, validation runs in sequence:
uv sync # install eventregistry
dg check defs # validates Python + Dagster definitions
dbt compile --select stg_trending_events # validates the SQL model
dg check defs is particularly useful here because it validates the full integration in one command: NewsApiResource is correctly defined, trending_events loads without import errors, and the schedule referencing both is valid. If any of the parallel writes had an error, dg check surfaces it immediately.
The total sequence (plan, 8 parallel writes, 3 sequential validation steps) is faster than writing and validating each file one at a time, and it's easier to debug because there's a clear boundary between "writing phase" and "checking phase."
Applying this pattern yourself
When you're about to start a task that touches multiple files, ask:
- Is the full design knowable before I write the first file?
- If yes, can all the files be written simultaneously once the design is settled?
- What validation steps run after, and in what order?
If you can answer those three questions, you have the structure of a plan. Giving the agent this framing ("design first, then write everything, then validate") produces more consistent results than letting it discover the design file-by-file as it writes.